Method
Given instructions and RGB-D observations, OmniManip utilizes VLM and VFM to identify task-relevant objects and decompose the task into distinct stages. During each stage, OmniManip extracts object-centric canonical interaction primitives as spatial constraints and employs the RRC mechanism for closed-loop planning. For execution, the trajectory is optimized by constraints and updated via a 6D pose tracker, achieving closed-loop execution.
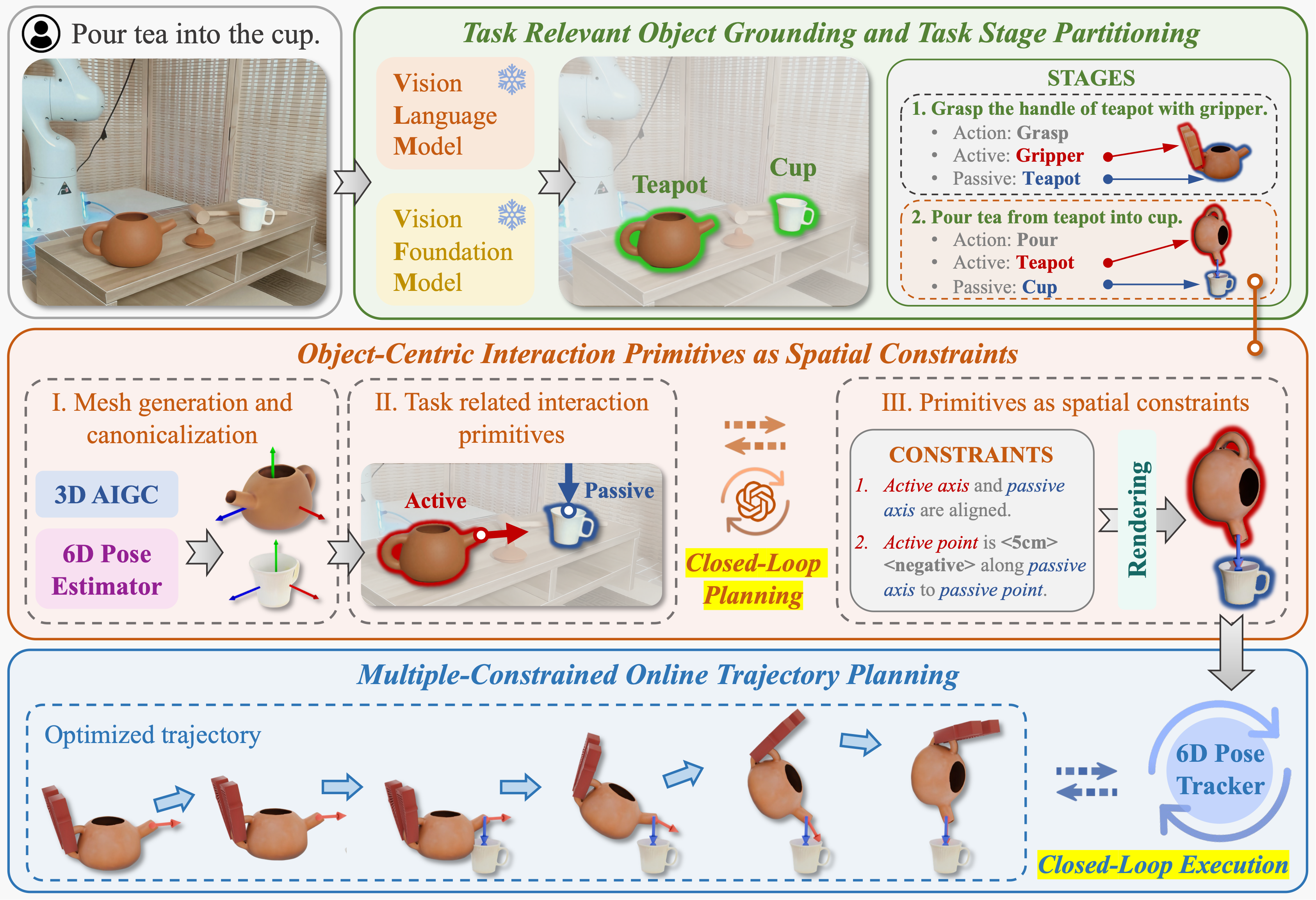
Dual Closed-loop System Design
Closed-loop Planning.

Closed-loop Execution.
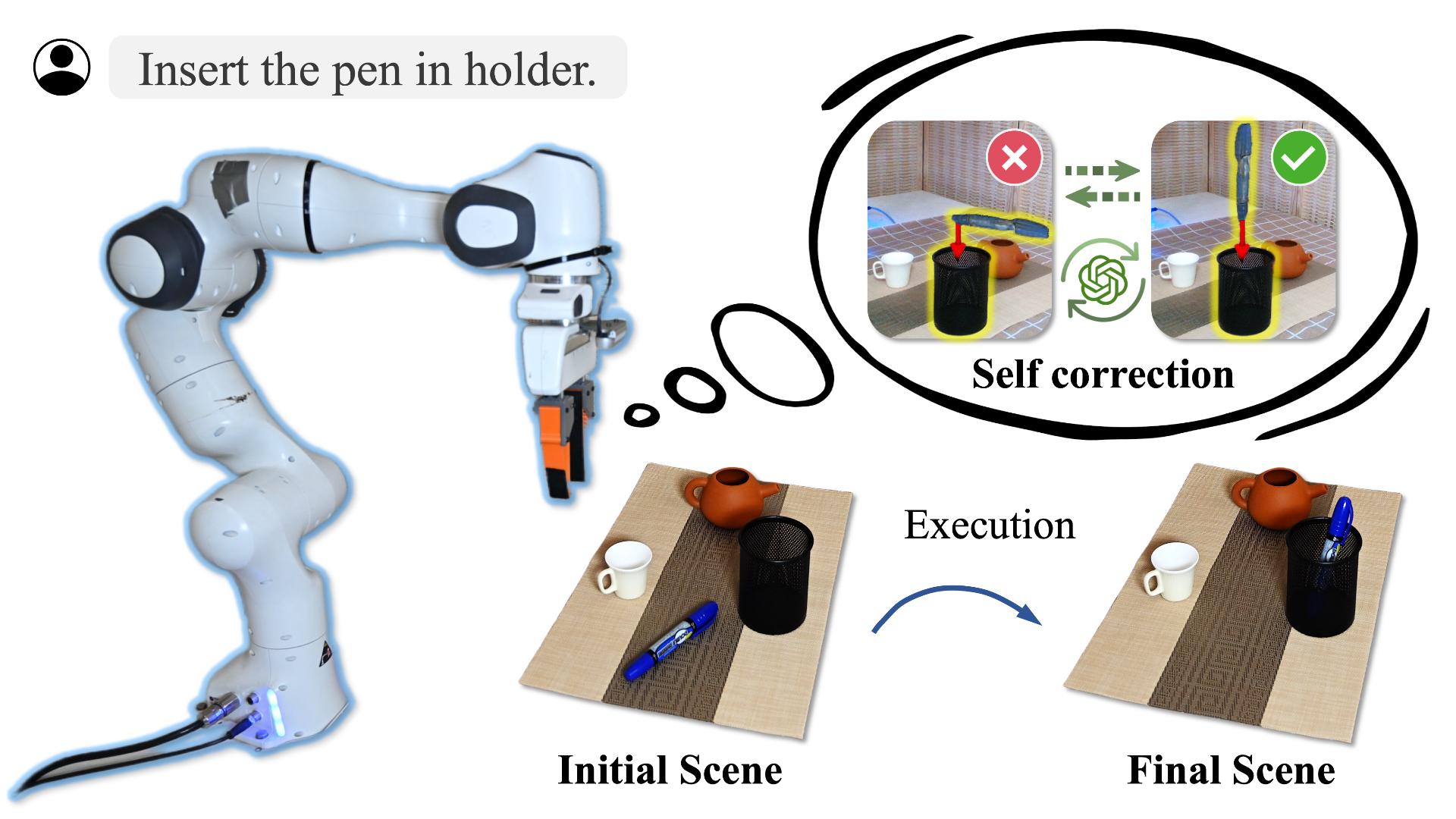
Application to Long-horizon Task
With the integration of a VLM-based high-level planner, OmniManip can accomplish long-horizon tasks. The high-level planner is responsible for task decomposition, while OmniManip executes each subtask. Below are two examples of long-horizon tasks.
Subtasks:
- “Open the lid”
- “Pour the rice”
- “Add the water”
- “Close the lid”
- “Click start button (top left corner)”
- “Wait 20 minutes”
- “Open the lid”
Subtasks:
- “Insert pen into holder”
- “Throw paper ball into bin”
- “Open drawer”
- “Place toy into drawer”
- “Close drawer”
Cross-embodiment Capabilities
OmniManip is a hardware-agnostic approach that can be easily deployed on various types of robotic embodiments. It utilizes the common-sense understanding capabilities of Vision-Language Models (VLM) to achieve open-vocabulary manipulation. We have implemented this operational framework on AgiBot's dual-arm humanoid robot.
Simulation Data Collection
OmniManip can be seamlessly applied to large-scale simulation data generation. Our follow-up work will be released soon, please stay tuned.
Join Our Team
We are seeking highly self-motivated interns and offer ample hardware and computing resources. If you're interested, please contact us at hao.dong@pku.edu.cn or pmj@stu.pku.edu.cn.